Analysing fNIRS data from COBI Studio in R (Part 1)
 Some noisy fNIRS data
Some noisy fNIRS data
I am currently conducting a study that uses fNIRS to indirectly measure cognitive activity during a decision-making task. The fNIRS setup that we have is from BioPac, and though it seems to work well, the data files that are generated are made to be compatible with the software that the company also sells (convenient!).
This is irritating for a number of reasons. Firstly, the analysis software requires a license, meaning additional costs to install it on the computer of a research or graduate student who might be conducing an fNIRS study and want to analyse their data. Secondly, and perhaps more importantly, I dislike proprietary file formats. There are many established tools for analysing fNIRS data. They expect a standard format for the data (.nirs or .snirf).
Finally, most of the established analysis tools for fNIRS require MATLAB, so even if I convert the file format into .nirs, I would need to use MATLAB to analyse the data. I’m could do this, but I’m not normally a MATLAB user, so there’s an additional time investment, along with the fact that MATLAB has an associated cost and computing resource requirements: this is a barrier to entry for students or even sharing code/analysis with other academics (who I work with).
The goal:
Essentially, I would like to be able to:
- import the nirs data files from COBI studio into R
- identify the baseline values that are recorded at the beginning of the study
- identify the optodes and their associated values through the duration of the study
- link the event markers to the data
- visualise the data
- apply MBLL to the raw nirs data, to calculate Oxy and DeOxy values based on: the optode setup, relevant coefficient values, baseline values
- apply signal processing, such as: high/low pass filters, SMAR etc.
- Define event windows based on trial types and calculate averages across these different trials
1. import the nirs data files from COBI studio into R
The .nir file
The first step in this process was understanding what data are generated from COBI Studio. A standard study will include 3 files:
- a .nir file which is raw nirs data from each sensor/receptor combination at 730nm, 850nm and the ambient light sensor.
- a .oxy file which includes automatically calculated oxy and deoxy calculations for each optode, based on the data in the .nirs file and the baseline values recorded at the start of the experiment (also present in the .nir file).
- a .mrk file which contains the markers that were sent during the study and their associated time value.
I found a very good breakdown of the files in a Master’s thesis by Vural (2018) which included some useful images of the files. Here is an example if the .nir file:

The .nir file format
As we can see from the image:
there is a section of information including the date and the current/gain settings for this specific recording session.
There is an initial section recording baseline values
There is a row where the baseline values are averaged
The subsequent rows are the data from the study
If we look at the columns:
The first column is a time index.
Each 3 subsequent columns represent an optode, with values from 730nm, 850nm and the ambient light sensor.
Reading the .nir file
With the above information, I could set about importing the data. The first step was to import the data in a raw format using readlines():
nirfile <- "CWILSON_1_test3_02210957.nir"
nir1 <- readLines(nirfile, skipNul = TRUE) # read lines and skip empty rows
nir1 <- nir1 %>% as_tibble(nir1) # convert to tibble for ease of use later
head(nir1)# A tibble: 6 x 1
value
<chr>
1 "fnirUSB.dll log file"
2 "Start Time:\tFri Feb 21 09:57:18 2020"
3 ""
4 "Start Code:\t1534.887629\t1534734"
5 "Freq Code:\t2338343.000000"
6 "Current:\t17" The next step, which makes the file easier to separate and organise, is to assign a numerical value to each row:
nir1 <- mutate(nir1, id = row_number()) # assign a value based on the row number
head(nir1)# A tibble: 6 x 2
value id
<chr> <int>
1 "fnirUSB.dll log file" 1
2 "Start Time:\tFri Feb 21 09:57:18 2020" 2
3 "" 3
4 "Start Code:\t1534.887629\t1534734" 4
5 "Freq Code:\t2338343.000000" 5
6 "Current:\t17" 62. Identify the baseline values recorded at the beginning of the study
Now we need to use the id column to make it easy to idenitfy which rows contain the baseline values, using str_detect(). We store the rows where the baseline begins and ends, and store this information as baselineNirsValues. In the last line, we can use strsplit() and unnest() to separate the values into columns:
bStartRow <- nir1 %>% filter(str_detect(.$value, 'Baseline values')) %>% select(id)
bEndRow <- nir1 %>% filter(str_detect(.$value, 'Baseline end')) %>% select(id)
baselineNirsValues <- nir1 %>% filter(id > bStartRow$id & id < bEndRow$id)
baselineNirsValues <- baselineNirsValues %>% mutate(value = strsplit(as.character(value), "\t")) %>% unnest(value)
head(baselineNirsValues)# A tibble: 6 x 2
value id
<chr> <int>
1 0 31
2 3626.25 31
3 0 31
4 3998.25 31
5 2291.40 31
6 0 31Since I am not certain whether this baseline will be useful (my study has an inter-trial period built in the the design, with a view to potentially using a moving baseline), I will come back to it another time.
3. Identify the optodes and their associated values through the duration of the study
We can use a similar approach to above to get the main nir data from each of the optodes. The end of the baseline can be used as the start point, and the last row can be used as an end point:
nirsEndRow <- nir1 %>% filter(str_detect(.$value, '-1 Device Stopped')) %>% select(id)
nirsDataValues <- nir1 %>% filter(id > bEndRow$id & id < nirsEndRow$id)
head(nirsDataValues)# A tibble: 6 x 2
value id
<chr> <int>
1 "17.189\t3320.0\t2090.0\t3899.0\t2266.0\t77.0\t3501.0\t1620.0\t191.0\t2~ 33
2 "17.699\t3305.0\t2190.0\t3904.0\t2273.0\t64.0\t3490.0\t1624.0\t201.0\t2~ 34
3 "18.209\t3292.0\t2207.0\t3872.0\t2272.0\t83.0\t3492.0\t1627.0\t197.0\t2~ 35
4 "18.719\t3323.0\t2281.0\t3891.0\t2284.0\t79.0\t3503.0\t1641.0\t206.0\t2~ 36
5 "19.229\t3288.0\t2216.0\t3855.0\t2278.0\t59.0\t3501.0\t1636.0\t199.0\t2~ 37
6 "19.739\t3249.0\t2234.0\t3895.0\t2276.0\t55.0\t3496.0\t1630.0\t197.0\t2~ 38However, the data are not labelled or presented in a useful way. We can use the image above to understand what each column represents. So we want the first column to be a time reference, and each 3 subsequent columns are values from 730nm, 850nm and the ambient light sensor, respectively. The below code seperates the data into columns and labels them appropriately:
# separate nirs data columns
## first column is time from start in seconds
nirsDataValues <- separate(nirsDataValues, col = value, sep = "\t", into = c("t", "op_1_730","op_1_ambient","op_1_850","op_2_730","op_2_ambient","op_2_850","op_3_730","op_3_ambient","op_3_850","op_4_730","op_4_ambient","op_4_850", "op_5_730","op_5_ambient","op_5_850", "op_6_730","op_6_ambient","op_6_850", "op_7_730","op_7_ambient","op_7_850", "op_8_730","op_8_ambient","op_8_850","op_9_730","op_9_ambient","op_9_850","op_10_730","op_10_ambient","op_10_850","op_11_730","op_11_ambient","op_11_850","op_12_730","op_12_ambient","op_12_850","op_13_730","op_13_ambient","op_13_850","op_14_730","op_14_ambient","op_14_850","op_15_730","op_15_ambient","op_15_850","op_16_730","op_16_ambient","op_16_850"), extra = "merge")
head(nirsDataValues)# A tibble: 6 x 50
t op_1_730 op_1_ambient op_1_850 op_2_730 op_2_ambient op_2_850 op_3_730
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 17.189 3320.0 2090.0 3899.0 2266.0 77.0 3501.0 1620.0
2 17.699 3305.0 2190.0 3904.0 2273.0 64.0 3490.0 1624.0
3 18.209 3292.0 2207.0 3872.0 2272.0 83.0 3492.0 1627.0
4 18.719 3323.0 2281.0 3891.0 2284.0 79.0 3503.0 1641.0
5 19.229 3288.0 2216.0 3855.0 2278.0 59.0 3501.0 1636.0
6 19.739 3249.0 2234.0 3895.0 2276.0 55.0 3496.0 1630.0
# ... with 42 more variables: op_3_ambient <chr>, op_3_850 <chr>,
# op_4_730 <chr>, op_4_ambient <chr>, op_4_850 <chr>, op_5_730 <chr>,
# op_5_ambient <chr>, op_5_850 <chr>, op_6_730 <chr>, op_6_ambient <chr>,
# op_6_850 <chr>, op_7_730 <chr>, op_7_ambient <chr>, op_7_850 <chr>,
# op_8_730 <chr>, op_8_ambient <chr>, op_8_850 <chr>, op_9_730 <chr>,
# op_9_ambient <chr>, op_9_850 <chr>, op_10_730 <chr>, op_10_ambient <chr>,
# op_10_850 <chr>, op_11_730 <chr>, op_11_ambient <chr>, op_11_850 <chr>, ...One of the things we will see in the marker file later, is that the markers are recorded using a time index (like the first column of the nirs data) and also a row index, which starts at the first row of our nirs data (i.e. the first row after the baseline ends). To make it easier to join the marker data with the nirs data later, we are going to add a row index to match this, called data_row:
# create a new column called data_row to match the markers
nirsDataValues <- mutate(nirsDataValues, data_row = row_number())Finally, although the data are easier to read when they are displayed in a wide format(as above), analysis is easier if the data are in a long format. The next code will convert the data to long format to make it easier to analyse and visualise:
nirs_long <- nirsDataValues %>%
pivot_longer(
cols = op_1_730:op_16_850,
names_to = c("optode", "freq"),
names_pattern = "op_(.*)_(.*)",
values_to = "nir_value"
)
head(nirs_long)# A tibble: 6 x 6
t id data_row optode freq nir_value
<chr> <int> <int> <chr> <chr> <chr>
1 17.189 33 1 1 730 3320.0
2 17.189 33 1 1 ambient 2090.0
3 17.189 33 1 1 850 3899.0
4 17.189 33 1 2 730 2266.0
5 17.189 33 1 2 ambient 77.0
6 17.189 33 1 2 850 3501.0 4. Link the event markers to the data
To link the event markers to the data, we need to identify when the marker data starts and ends in the marker file and then to separate in into useful columns:
markfile <- "CWILSON_1_test3_02210957.mrk"
mrk1 <- read_lines(markfile)
# convert to tibble
mrk1 <- mrk1 %>% as_tibble(mrk1)
# add id column
mrk1 <- mutate(mrk1, id = row_number())
# marker start row
mStartRow <- mrk1 %>% filter(str_detect(.$value, 'Freq Code:')) %>% select(id)
# get marker data from start row to end of file
markerValues <- mrk1 %>% filter(id > mStartRow$id & id <= max(id))
# separate marker data into columns
markerValues <- separate(markerValues, col = value, sep = "\t", into = c("t","marker", "data_row"), extra = "merge")
# make sure data_row is an integer and not a character
markerValues$data_row <- as.integer(markerValues$data_row)
head(markerValues)# A tibble: 6 x 4
t marker data_row id
<chr> <chr> <int> <int>
1 17.206 + 1 7
2 112.001 , 187 8
3 112.006 - 187 9
4 119.531 2 201 10
5 149.558 5 260 11
6 149.562 8 260 12If we wish, we can use the data_row column we created in the nirs file to link with the markers. The reason that we might want this is that the fNIRS typically records at a resolution of 2Hz, which is one data point every 500ms. However, the markers could be sent in between that 500ms window and, as such, will not align to a nirs reading at the exact time the marker was sent. If we look at a particular data row in the marker file, and the nirs file, we can see that they don’t align exactly in time. Note that in the marker file above, the first marker is sent at 17.206 seconds (t). However, we can see that the closest time point in the nirs data file is 17.189 seconds, meaning the marker was recorded 17ms before the next nirs data point was recorded:
nirs_long %>%
filter(data_row == 1) %>% head()# A tibble: 6 x 6
t id data_row optode freq nir_value
<chr> <int> <int> <chr> <chr> <chr>
1 17.189 33 1 1 730 3320.0
2 17.189 33 1 1 ambient 2090.0
3 17.189 33 1 1 850 3899.0
4 17.189 33 1 2 730 2266.0
5 17.189 33 1 2 ambient 77.0
6 17.189 33 1 2 850 3501.0 As such, we can use the data_row column to match the marker to the closest nirs data point. Because the marker data and the nirs data both have a column called data_row we can join them together using the left_join:
## add markers to nirsdata
mrk2 <- markerValues %>% select(data_row, marker)
nirs_with_markers <- left_join(nirs_long, mrk2, by = "data_row")
head(nirs_with_markers)# A tibble: 6 x 7
t id data_row optode freq nir_value marker
<chr> <int> <int> <chr> <chr> <chr> <chr>
1 17.189 33 1 1 730 3320.0 +
2 17.189 33 1 1 ambient 2090.0 +
3 17.189 33 1 1 850 3899.0 +
4 17.189 33 1 2 730 2266.0 +
5 17.189 33 1 2 ambient 77.0 +
6 17.189 33 1 2 850 3501.0 + Note: I’m not sure if I am going to maintain this practice in real analysis, because I need to fully explore the implications for aligning the markers with the fNIRS sample rate. However, I will keep this for now, as I continue to explore analysing the data
5. Visualise the raw data
Finally, for this post, the next step was to visualise the nirs data by each optode and wavelength. First, some clean up of variable types. Optode was kept as an integer so it will display in correct order.
## clean up variable types
nirs_with_markers$t <- as.double(nirs_with_markers$t)
nirs_with_markers$optode <- as.integer(nirs_with_markers$optode)
nirs_with_markers$freq <- as.factor(nirs_with_markers$freq)
nirs_with_markers$nir_value <- as.integer(nirs_with_markers$nir_value)
nirs_with_markers$marker <- as.factor(nirs_with_markers$marker)Next, we can use ggplot to make a plot that displays the value for each of the 3 light frequencies (730, 850 and ambient). Using facet_wrap we can get a plot for each of the 16 optodes:
nirs_with_markers %>%
ggplot(aes(x = t, y = nir_value, color = freq)) +
geom_line() +
facet_wrap(.~ optode) 
To add the markers, we use a vline geom, but need to use the ggnewscale package to allow the colours attribute of the vline to not get mixed up with the colour attribute of the lines already on the plot. Linetype and colour of the vline is set by marker, allowing us to see different markers on the plot. We can also adjust alpha value to increase transparency of markers:
library(ggnewscale)Warning: package 'ggnewscale' was built under R version 4.1.3nirs_with_markers %>%
ggplot(aes(x = t, y = nir_value, color = freq)) +
geom_line() +
ggnewscale::new_scale_color() +
geom_vline(data = nirs_with_markers %>% filter(!is.na(marker)), aes(xintercept = t, linetype = marker, colour = marker), alpha = 0.1) +
facet_wrap(.~ optode) 
Then, we can adjust the look of the plot using theme:
nirs_with_markers %>%
ggplot(aes(x = t, y = nir_value, color = freq)) +
geom_line() +
ggnewscale::new_scale_color() +
geom_vline(data = nirs_with_markers %>% filter(!is.na(marker)), aes(xintercept = t, linetype = marker, colour = marker), alpha = 0.1) +
facet_wrap(.~ optode) +
theme_minimal()
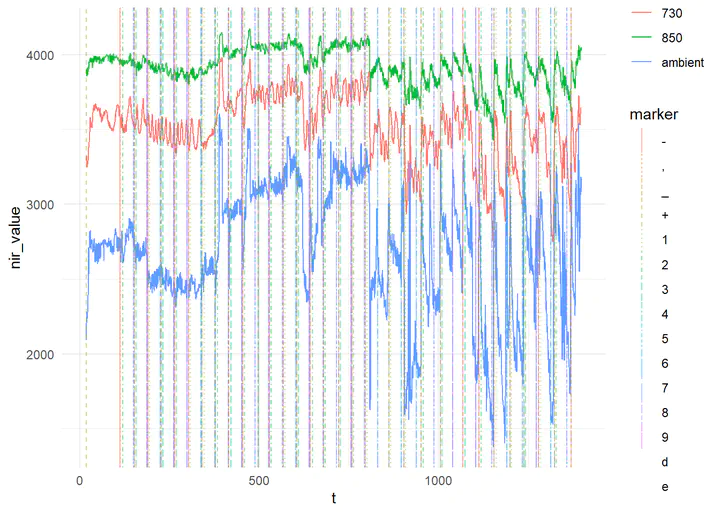
Finally, to show that the markers are actually on the plot (but hard to see when the plot is small), we can look at just 1 optode:
nirs_with_markers %>%
filter(optode == 1) %>%
ggplot(aes(x = t, y = nir_value, color = freq)) +
geom_line() +
ggnewscale::new_scale_color() +
geom_vline(data = nirs_with_markers %>% filter(!is.na(marker)), aes(xintercept = t, linetype = marker, colour = marker), alpha = 0.5) +
theme_minimal()
References
Christopher J Wilson
Associate Professor of Psychology
Experimental psychologist with interest in decision making, risk, attention, perception and virtual reality. Open to collaborations with researchers, third sector organisations and industry in the areas of financial decision-making, efficacy of financial education, the effects of psychological stress/distress on financial behaviour. I code lab & web-based behavioural studies using JavaScript / python. I use fNIRS, Eyetracking and VR in research. I conduct analysis in R. https://research.tees.ac.uk/en/persons/chris-wilson